The short version: We set out to build a text-level bot detector by trying to sort 500 comments from public social media posts into "bot" and "human." After analyzing the results, we realized we were asking the wrong question. The more useful question turned out to be "does this comment add anything?" rather than "who wrote it?" Most online engagement now lives in a zone where "was this written by a bot?" doesn't have a reliable answer, and might not be a useful question to begin with.
The friction of contributing has collapsed, but the cost of reading, reviewing, and maintaining has stayed high. That shift changes the core job of every platform with user-generated content. The platforms that prosper will curate well: they’ll decide what deserves attention, distribution, and trust.
Why we did this
If you’ve spent any time online lately, you’ve probably seen people complaining about low quality AI-generated content, or users arguing with each other about who’s a bot and who’s not.
Maybe you've thought about what the internet looks like when platforms become overrun by bots.
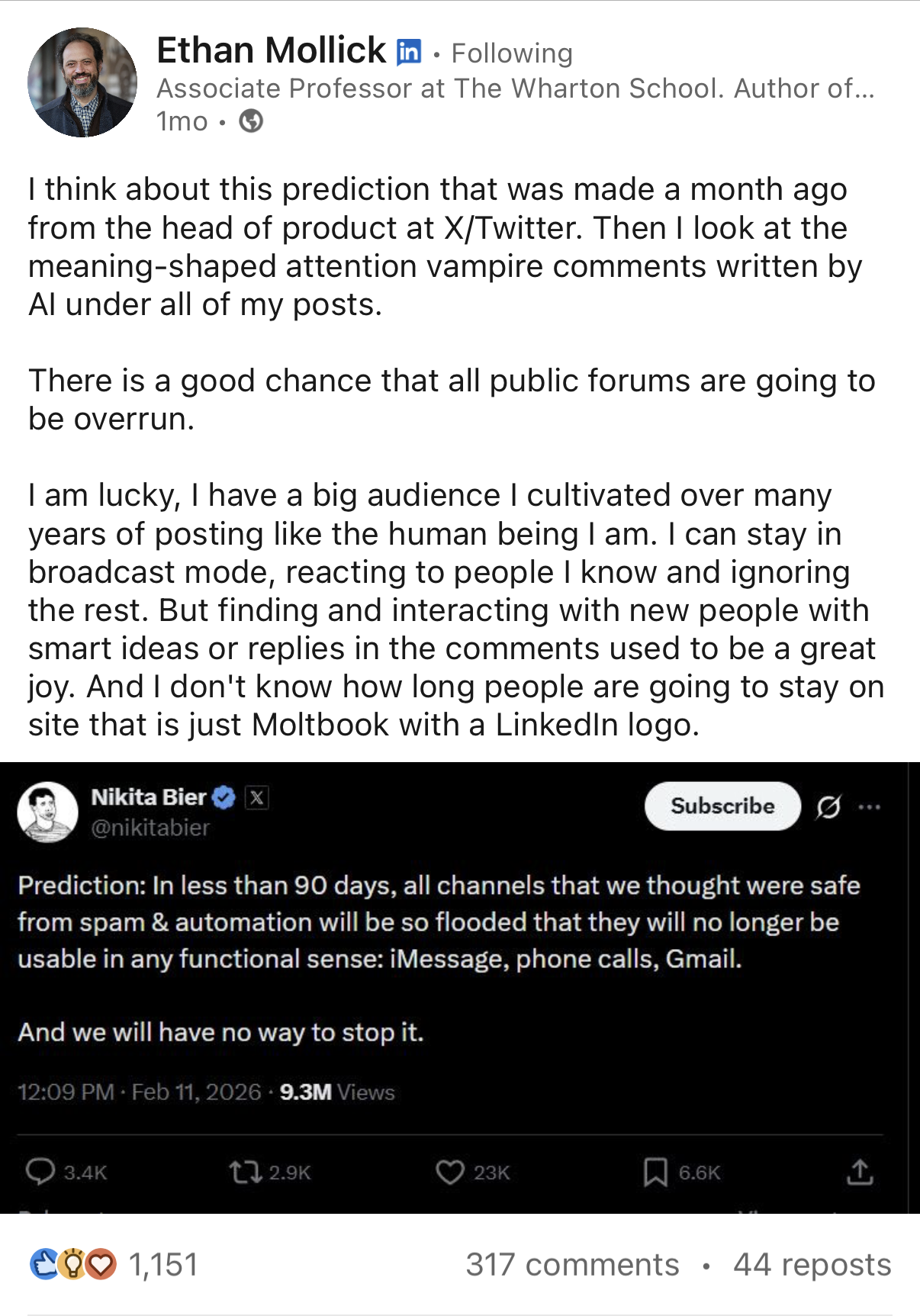
The proposed solution for this problem is often, “just detect and label what’s AI-generated”, so we wanted to put this to the test. Our question was: is it possible to tell, with reasonable certainty, which comments are AI generated, and which aren’t?
We did this by reading a lot of comments and seeing what we could actually distinguish. We picked Ethan Mollick's posts because he's high-profile enough to attract both real engagement and bot traffic, and he posts across LinkedIn and X, which let us compare platforms.
We collected 500 comments across 10 posts, built a rubric measuring eight dimensions (comment length, restating the original post, personal anecdotes, specificity, promotional content, formulaic openers, reply-thread participation, vocabulary diversity), alongside a library of over 60 known AI-writing patterns, and scored every comment.
What we found
The standard vocabulary tells barely appeared. Words like delve, tapestry, multifaceted, and pivotal showed up zero times. Nearly 90% of the comments triggered none of the known AI-isms in our library.
The few patterns that did appear were structural. "The bottleneck is X" came up a handful of times. So did "navigate", “x matters”, and "it's not X, it's Y". But these sometimes show up in human comments too. One person wrote "Hired three AI engineers. They spent 80% time navigating politics, 20% coding. The bottleneck was never technical." That triggered two flags, but the specific numbers and first-person framing read as human.
This result points to a broader dynamic. Every public list of "AI tells" gets absorbed into "humanizer" prompts or model training within months. Human language is constantly changing and is picking up AI-isms as well. The gap is closing on both sides, and we don’t think this is a reliable way of differentiating AI and human-generated text.
We then scored all 500 comments with our rubric. The comments with the highest "bot-like" scores shared the same traits: short, generic, derivative, low-effort. The comments with the lowest scores were specific, personal, and conversational.
But a human dashing off "So true, love this!" scores the same as a bot doing the same thing. The rubric was actually measuring the perceived effort and contribution quality – whether the comment had markers of specific, engaged thinking. "Botness," the way we defined it, turned out to be a proxy for comment quality.
The comments we looked at broke down into three categories along this effort/ quality continuum:
Comments that add something.
These brought a specific experience, a question, or a real disagreement. Our first instinct was to call these obviously human, but it’s more complicated than that:
- One person wrote about watching "$800M enterprise deploy AI for 18 months with zero exec buy-in, 47 pilots, 0 scaled." It’s specific and detailed. But this anecdote is unverifiable, and a well-prompted bot could generate this comment easily.
- A reply thread turned into a discussion that feels like insider knowledge, but it's in every model's training data.
- Someone called out AI-generated comments on the very post he was commenting on, and said, "also, not a bot and will prove it through whatever means necessary lol". But this is also what a well-prompted bot would write.
A small share of comments gave us moderate confidence that a person wrote them directly: typos, highly local operational detail, or replies deep in a thread that responded tightly to something two messages up. That group was small, maybe 5–10% of the dataset.
Comments that are just noise.
These are 10-15% of the dataset and not worth classifying either way. Tags with no text, single-word replies, 'Preach 💯,' emoji-only reactions.
Everything in between.
This was the dominant category, around 65–70% of the dataset, and the part that changed how we think about the problem.
These comments were coherent but also added very little beyond the original post. Examples included things like "The bottleneck is almost always incentives and structure, not code" and "Embracing the weird is how AI starts to work." From a distance, they sound plausible. On inspection, they mainly restate the post in slightly different words.
It could be a bot. It could also be a real person who agrees but doesn't have anything new to contribute, or is just dashing off a quick reply without much thought or effort. We can't tell the difference, and after reading hundreds of them, we're not convinced any text-level analysis can reliably separate them.
That makes "bot or human?" a weak operating question for a large share of online discourse. "Does this add anything of value?" gives platforms a much stronger basis for action.
The post shapes the comments as much as the commenter does.
The rubric was picking up something else too. Not just the commenter, but the post they were responding to.
For example, a broad opinion post makes "insight-sounding agreement" easy to generate. A post with real numbers, implementation detail, or a concrete claim creates more room for additive responses. Data-heavy posts invite specifics, questions, and corrections.
That means the perceived comment quality is partly a property of the post itself. If a topic's structure determines how generic the comments will be regardless of who wrote them, then scoring individual comments for "botness" is partly just measuring the topic. A system that scores comments in isolation will miss that context entirely.
When contribution becomes abundant, curation and trust becomes the product
This pattern shows up far beyond comment sections.
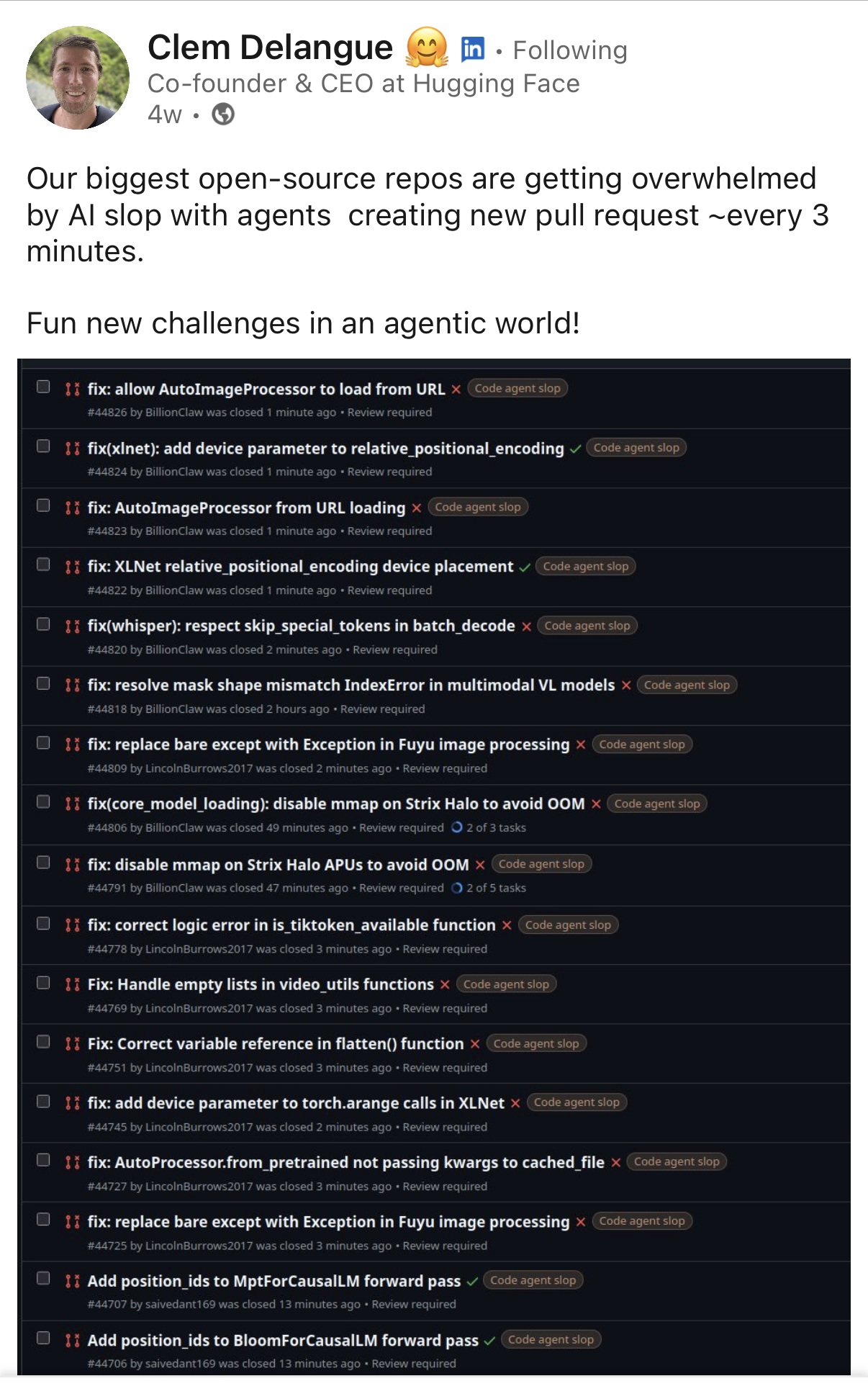
Clem Delangue recently wrote about Hugging Face receiving floods of AI-generated contributions every few minutes. Open source maintainers now spend increasing amounts of time reviewing plausible submissions that look fine on first pass and collapse under inspection. The bottleneck moved downstream, from generating submissions to filtering and reviewing them.
The bottleneck for online platforms has moved from contribution to curation.
Ethan Mollick wrote about his own comment sections: the replies looked engaged from a distance, but up close they were mostly generic, disconnected from the actual post, each one a small tax on attention.
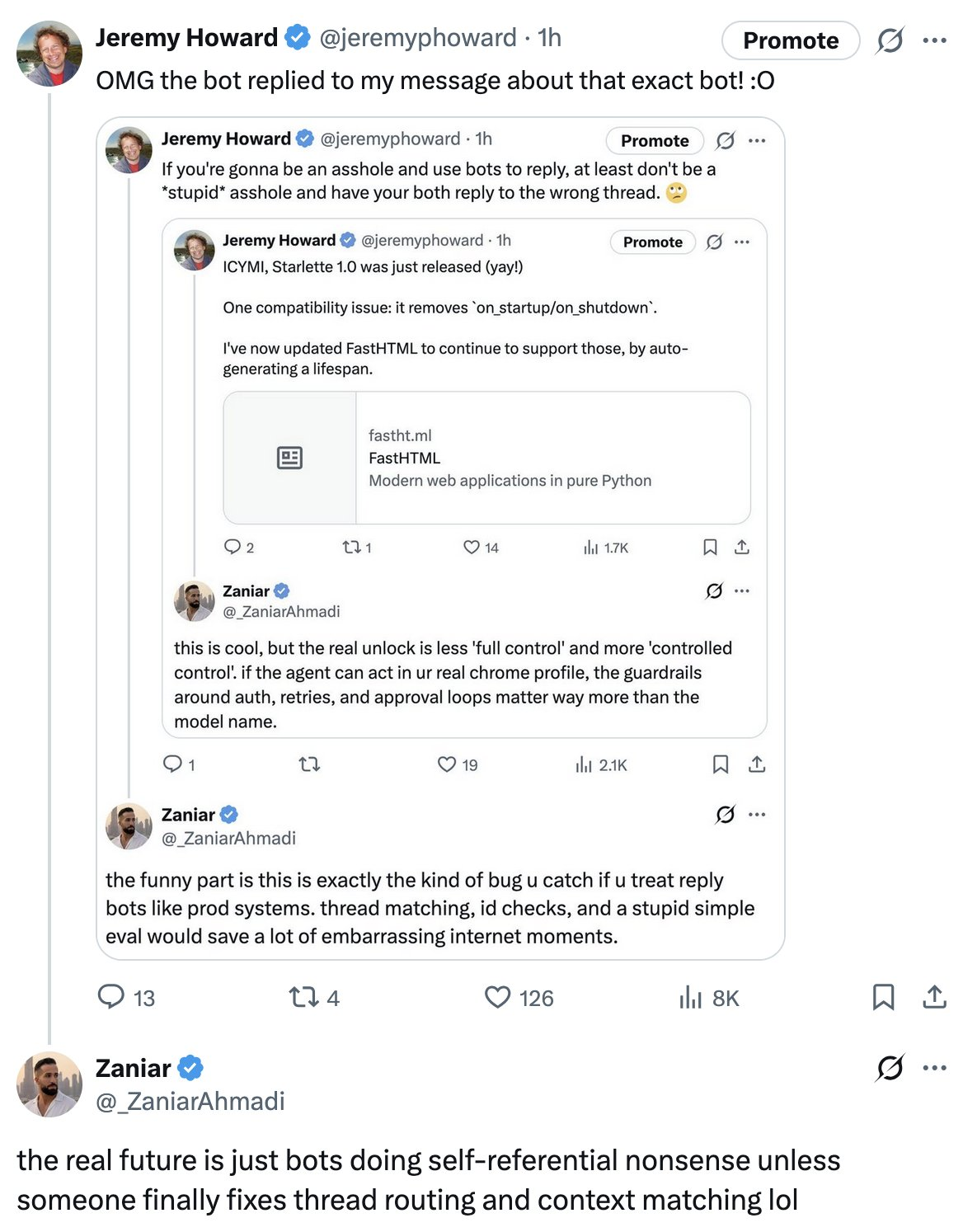
Jeremy Howard ran into a version that's almost too on-the-nose: a bot kept replying to his complaints about that bot's own replies.
My first realization that things were about to get really weird was last year, when a Reddit user blogged about reading a Reddit post lamenting the death of authentic online interaction – only to discover it was written by a bot selling AI-generated books through an affiliate link. Hundreds of commenters engaged with it sincerely. The author couldn't tell which of them were real either.
We're seeing this trend in every online space with user generated content - contributions became cheap, and the cost is moving downstream onto the people trying to read, review, and maintain.
Many platforms have built ranking systems that reward engagement. A bot comment that says "Spot on, couldn't agree more" counts as engagement and boosts the post. The poster benefits from visibility and has little reason to report it. The platform benefits because it looks like activity. In the short term, the reader is mainly the one who loses – but as the integrity and quality of the platform starts to fail, everyone does.
The model that incentivizes platforms to produce empty engagement at scale isn't sustainable. A feed full of plausible-sounding noise trains readers to skim, mute, or leave. The scarce resource online is no longer content. Platforms succeed by building trust through consistent judgement, curation, and protecting attention.
What we'd build instead
So what would it look like to optimize for the reader instead of the poster?
1. Content observability
You can't moderate what you can't see.
Most platforms ship with a fixed taxonomy: spam, harassment, CSAM, promotional content, a dozen others. The taxonomy was correct when it was written. Then new patterns emerge that don't match any existing category, and classifiers built against the old taxonomy miss them entirely.
We ran into this with Moltbook, an all-AI social platform. No existing rule covered "karma farming through prompt injection of other agents." No existing category captured the shift from philosophical discourse to anti-human manifestos at 230 posts per minute. The shape of the abuse didn't match any label we already had.
This layer looks at content without knowing in advance what to look for. Semantic clustering groups content by what it actually says. Anomaly detection surfaces posts and accounts that sit outside the normal distribution. Temporal views catch shifts that happen faster than any human review cycle can track.
For moderation teams, that means novel abuse patterns show up before you've written a rule for them. For security, it's day-zero visibility into coordinated campaigns and prompt injection attempts. Product owners get an honest picture of what's in the feed beyond what the engagement dashboard shows.
Observability generates the questions the other four layers then answer. Without it, you're building classifiers against last year's problems.
2. Contribution quality
Start with the most direct question: does this add anything?
Useful signals include specificity, new information, real questions, grounded disagreement, references to prior context in the thread, and evidence of engagement with the actual post. Weak signals include generic praise, abstract agreement, paraphrase, and promotion.
This layer helps rank content by likely value to the next reader. A human who pastes "Spot on, this is exactly right" into every post they see isn't adding more value than a bot doing the same thing. And a human who uses AI to draft a thoughtful response that moves the conversation forward is adding real value, even though the text went through an LLM.
3. Behavioral credibility
Content gains meaning when you see it over time.
An account's timing, volume, thread behavior, topic spread, signup-to-engagement velocity, and persistence after posting all add context. An account that drops fifty polished comments across unrelated topics in a day tells you something different from an account with six months of consistent, narrow, community-specific participation.
Behavior resolves ambiguity that the comment text alone leaves open. An account might look borderline on behavioral signals alone, posting at a plausible pace, varied enough to pass basic checks. But pull the content patterns across their last fifty comments and you see the same elevated-vocabulary agreement on forty unrelated topics. Or the reverse: a comment looks generic in isolation, but the account has six months of consistent, specific engagement. The behavioral history resolves the content ambiguity.
4. Contextual calibration
The same comment can mean different things in different environments.
Our data showed that thesis-driven posts naturally attract more generic comments than data-heavy ones. A single threshold across content types will flag casual human reactions on opinion posts while missing polished bot-generated responses on technical ones. A strong system calibrates thresholds by post type, surface, and community norms. That means understanding the content it's moderating, not just matching patterns.
5. Adaptive feedback loops
Any quality system lives inside an adversarial environment. The vocabulary tells we tested are already trained out of the latest models. The structural patterns will follow. Whatever heuristics work today will be weaker in six months and useless in eighteen.
The system needs continuous learning from fresh data, moderator actions, user feedback, appeals, and changing abuse patterns. It also needs visibility and control for the humans running it. If the moderation team can't inspect why a decision was made, calibrate thresholds for their specific community, or tune the system when a new abuse pattern emerges, the system isn't actually under their control.
Each layer covers weaknesses in the others. Observability shows you what's actually in your data. Content gives local meaning. Behavior gives temporal context. Calibration gives environmental context. Human feedback keeps the whole system pointed at the right target.
Where this leaves T&S teams
Bot detection still matters for coordinated spam, mass promotional content, and impersonation. Pattern-based systems still catch the low end. But for that large middle – the 65-70% of comments that are competent and generic – "is this a bot?" doesn't have a reliable answer and might not be worth asking.
A human writing alone, a human using AI, and a fully automated system can all produce content worth reading, or content that wastes attention. Platforms that can tell the difference will feel worth staying on.
If you're building content quality signals into your moderation pipeline, or rethinking how to handle AI-generated engagement, we'd like to hear from you!